

The Kubernetes Flywheel: How Community Access Drives Enterprise Adoption
- Steve Younger

- Jan 27
- 26 min read
Updated: Jan 27

Kubernetes adoption isn’t just continuing; it is accelerating into new territory. The latest CNCF Annual Cloud Native Survey, covering 2025 usage, reports that Kubernetes is running in production for 82% of container users and that 66% of organizations adopting AI are using Kubernetes to scale inference workloads. In other words, Kubernetes has moved beyond being simply the way teams run containers and has become the backbone of modern infrastructure, including AI. That shift is fundamental because Kubernetes is no longer a tool you bolt onto a stack; Kubernetes is the stack. It increasingly serves as the control plane for data, networking, security, observability, and AI workloads that need to run consistently from cloud to core to edge. Yet as Kubernetes becomes the default operating layer, a troubling trend is emerging around it: many of the infrastructure primitives that made Kubernetes practical, such as object storage, caching, ingress, network policy, stateful storage, and infrastructure as code, are becoming enterprise-first, turning into free but restricted offerings, or eliminating community tiers altogether. Whether this is driven by licensing changes, subscription gating, or open repositories being placed into a state where they cannot realistically evolve, the result is the same, and it is a strategic mistake.
The Kubernetes flywheel is real, and it starts in the home lab
There is an uncomfortable truth about how enterprise technology spreads, and it is one procurement teams rarely account for when they build evaluation frameworks and preferred vendor lists. Enterprise buying decisions are downstream from individual learning. The tools that make it into production at scale are often the tools that engineers have already touched, already struggled with, and already proven to themselves in environments where there is no committee, no sales cycle, and no pressure to justify a choice beyond whether it works.
The best engineers, SREs, and platform teams do not begin their evaluation journey with analyst reports or glossy reference architectures. They begin with hands-on experience. They spin up a tool in a home lab, build something real on a weekend, push it beyond the happy path, and break it in ways documentation never covers. They fix it, learn its failure modes, and understand where it shines and where it does not. That process creates the kind of confidence that cannot be manufactured by a product brief. It is personal, practical, and earned.
This is the Kubernetes adoption flywheel in its most natural form. People learn a tool, then they build with it. Building creates trust, and trust leads to recommendations. Recommendations turn into standards, and standards eventually become purchases. Learn leads to build, build leads to trust, trust leads to recommend, recommend leads to standardize, and standardize leads to buy. When the on-ramp is open, that flywheel spins quickly and almost invisibly, powered by curiosity and repetition across thousands of engineers.
When you introduce a paywall, a gated license, or terms that prohibit modification at the first step, you are not simply adding friction to a download. You are interrupting the flywheel before it can start. You are removing the conditions that create advocates, and replacing them with a barrier that forces people to make a budget decision before they have enough experience to justify one. Most will not fight through that barrier. They will route around it by choosing something else that they can install, test, and learn immediately.
In a Kubernetes era, that tradeoff is even more expensive than it looks. Tooling choices ripple outward into cluster architecture, platform engineering practices, security posture, operational processes, and day-two realities like upgrades, incident response, and cost control. The teams who influence those decisions are the teams with hands-on confidence, and their confidence is built through access. That is why mindshare matters so much right now. If you lose the practitioners at the learning stage, you are not just losing a potential customer. You are losing the engineers who would have made your product a default.

Tech Stacks Tip Callout:
Treat "Free" as an Architecture Property
When evaluating Kubernetes tooling, don't treat "free tiers" as a pricing detail. Treat them as an architectural property.
The quiet shift from “community-first” to “enterprise-first”
If you read enough release notes, licensing pages, and GitHub READMEs, you start to notice a pattern that is hard to unsee. The language changes first. A repository that once welcomed broad community participation begins to emphasize “supported configurations” and “commercial terms.” Features that used to ship in the same build start getting separated into tiers. Roadmaps narrow. Contribution paths become more restrictive, or the center of gravity quietly moves from the public repo to private development. Heinan Cabouly described this dynamic as a sustainability crisis reaching into the core of modern stacks, and it is a framing that resonates because it captures both the business pressure and the technical consequences.
The pattern itself is remarkably consistent. A project becomes ubiquitous, often because it is genuinely useful and because it is easy to download, run, and learn without asking permission. Enterprises then standardize it because it is already familiar to the engineers building and operating their platforms. Once that happens, the vendor begins to feel the squeeze. Support expectations rise, security obligations increase, compliance requirements expand, and monetization becomes harder in a world where hyperscale’s can package and resell the same capabilities with massive distribution. In response, the vendor tightens control, whether through licensing changes, feature gating, or turning the community edition into a cul-de-sac that is technically available but no longer viable for serious use. Then the community reacts in predictable ways, with forks, replacements, and a wave of migration churn that consumes time and focus across the industry.
This is no longer an abstract debate about open-source philosophy. It is showing up in real infrastructure components that sit directly on the critical path of Kubernetes adoption. These are not edge utilities or niche developer tools. They are foundational primitives that teams depend on for storage, networking, ingress, caching, and automation. When those primitives shift from community-first to enterprise-first, the change ripples outward into how platforms are learned, how they are evaluated, and ultimately how quickly the Kubernetes ecosystem can keep moving forward.
MinIO: maintenance mode and subscription tiering
MinIO became ubiquitous for a reason. It was fast, simple to deploy, and it gave engineers a practical way to bring S3-compatible object storage into Kubernetes clusters, CI pipelines, and home labs without waiting on anyone’s approval. That ease of access mattered because object storage is not a nice-to-have in modern stacks. It is a foundational primitive that quietly supports everything from backups and artifacts to analytics and ML datasets.
In early December 2025, that community posture changed in a very direct way. A commit to the minio/minio repository updated the README with a “Maintenance Mode” notice and stated that the project is under maintenance and not accepting new changes. It also spelled out what that means in practice: no new features or enhancements, no acceptance of pull requests, security fixes evaluated on a case-by-case basis, and issues and PRs no longer actively reviewed. The same notice pointed users toward MinIO AIStor for “enterprise support and actively maintained versions.”
If you visit the repository today, the message is still the same at the top. Shortly after that shift, MinIO introduced new subscription tiers for AIStor, including AIStor Free and Enterprise Lite, and framed them as a way to make the platform more accessible while aligning the product story explicitly with modern AI and deployment realities “from edge to core to cloud.”
But this is where the nuance matters for engineers. AIStor Free is free of charge, yet it is not a continuation of the old community experience. The AIStor Free Tier License Agreement grants permission to use the software only in standalone mode, defined as single-node deployments without distributed clustering or high availability. It also includes restrictions that prohibit modifying the software, reverse engineering it, or creating derivative works, and it forbids redistribution.
That may be a completely rational decision from a business standpoint. It offers a controlled on-ramp, limits operational and support exposure, and creates a clean path into paid tiers. But it is also a fundamentally different kind of “community tier” than what many engineers associate with open source. A free licensed binary can be an evaluation tool. An open community edition is a learning platform. One is designed to be consumed. The other is designed to be explored, extended, and sometimes contributed to.
In a Kubernetes-first world, this distinction is not academic. It directly impacts how the adoption flywheel spins. When a core building block moves from “download, run, inspect, and build” to “download, run, but do not modify or extend,” it changes who can get hands-on, how deeply they can understand the system, and whether they are willing to recommend it when they are sitting in the enterprise seat later.
Tech Stacks Tip Callout:
Single-Node Limits Teach the Wrong Lessons
A "free" or limited to a single-node deployment is not a learning tier, it's a mislearning tier.
HashiCorp: the license change that created OpenTofu
HashiCorp’s tooling sits in a uniquely influential place in modern infrastructure because it shaped how an entire generation thinks about provisioning. Terraform, in particular, became a common language for expressing infrastructure intent across clouds, on-prem environments, and everything in between. That ubiquity did not happen by accident. It happened because the barrier to entry was low, the code and workflows were widely accessible, and an ecosystem of providers, modules, and integrations could form around a stable foundation.
In August 2023, HashiCorp announced a major change to that foundation. The company stated it was changing the source code license for future releases of its products from Mozilla Public License 2.0 to Business Source License 1.1. HashiCorp framed the move as a way to ensure continued investment in the community and to keep products open and freely available, while addressing the reality that some vendors were commercializing HashiCorp’s work without providing meaningful contributions back. HashiCorp also made clear what the shift was intended to restrict: end users could continue to use, modify, and redistribute the code broadly, except in cases where it would be used to provide a competitive offering to HashiCorp, and vendors offering competitive services would no longer be able to incorporate future releases, including bug fixes and security patches.
This is the moment where “license nuance” stops being a legal footnote and becomes a platform-level concern. Infrastructure as code is not a peripheral tool. It becomes embedded in delivery pipelines, compliance workflows, security controls, and platform engineering standards. When the license governing that core tool changes, it introduces uncertainty for everyone building on top of it, including individuals learning it at home, startups building products around it, and enterprises betting on it for long-term automation.
The community response was fast and pragmatic. OpenTofu emerged as a fork effort explicitly aimed at keeping Terraform-style workflows under a governance and licensing model that the community could trust long-term. In its early announcement, the project positioned itself as a direct reaction to HashiCorp’s licensing move and emphasized principles that map to the core fears created by the shift: stability, open governance, impartial decision-making, and backwards compatibility. The message was not subtle. If the foundation can change unexpectedly, the ecosystem will seek a foundation that cannot.
By September 20, 2023, the Linux Foundation formally announced the formation of OpenTofu as an open-source alternative to Terraform, explicitly describing it as a community-driven response to Terraform’s license change from MPLv2 to BSL 1.1 and highlighting neutral governance as a central promise. The press release framed OpenTofu’s purpose in terms that go beyond cost: providing a reliable alternative that remains truly open, community-led, and safe for the broader ecosystem to build on without worrying about future surprise shifts.
This is why the takeaway is not simply “free vs paid.” It is trust, governance, and predictability. Kubernetes-era stacks are built from layers of dependencies that must remain dependable over long lifecycles. When a key layer signals that its community contract can change, engineers and organizations respond by hedging, forking, or migrating. That churn is expensive, but it is also rational. People are not only choosing a tool. They are choosing the long-term stability of the foundation they are going to teach, standardize, and bet their infrastructure on.
Redis: license turbulence → Valkey → (partial) course correction
Redis is a perfect case study because it sits in the category of software that people stop thinking about once it works. It becomes part of the background radiation of modern systems. It powers queues, rate limiters, caching layers, session stores, leaderboards, and coordination paths across countless applications. That kind of ubiquity is exactly what makes licensing and governance changes so sensitive. When a building block is everywhere, even small shifts ripple across home labs, startups, and the largest enterprises at the same time.
In March 2024, Redis announced that future versions would move away from the permissive BSD license and instead adopt a dual “source-available” model. Starting with Redis 7.4, new releases would be dual-licensed under RSALv2 and SSPLv1, and Redis stated plainly that it would no longer be distributed under BSD going forward. The company also acknowledged the practical implication that many engineers immediately recognized: this change meant Redis would no longer qualify as open source under the OSI definition, while arguing that the move was necessary to sustain the project and address the way large providers can commoditize popular open-source infrastructure.
The community response came quickly because the ecosystem had already learned what happens when a foundational primitive becomes less predictable to build on. Within days, the Linux Foundation announced its intent to form Valkey, explicitly framing it as an open-source alternative created in response to Redis Inc.’s recent license change. Valkey would continue development from the Redis 7.2.4 codebase and keep the project available under the BSD 3-clause license, preserving the kind of open on-ramp and redistribution certainty that much of the community wanted to protect.
Tech Stacks Tip Callout:
Governance Predictability Matters More Than Features
For foundational infrastructure, governance stability often matters more than feature velocity.
Then came what can best be described as a partial course correction. In May 2025, Redis announced that it would add AGPLv3 as an additional licensing option starting with Redis 8, explicitly pointing out that it is OSI-approved and that some users needed an OSI-approved license to operate comfortably. Redis described this as a tri-license approach that includes RSALv2, SSPLv1, and AGPLv3, bringing an open-source option back into the picture for Redis 8 and later.
Regardless of where you land emotionally on any one of these decisions, the broader dynamic is hard to ignore. When the on-ramp changes, the market creates new on-ramps. Engineers route around friction and uncertainty the same way packets route around congestion. If the path that used to be open becomes gated, constrained, or legally messy, the ecosystem does what it always does. It finds or builds an alternative that restores the ability to learn freely, build confidently, and standardize without fear that the foundation will shift underfoot.
Portworx: the community tier gets sunset
Portworx documentation is blunt: Portworx Essentials is discontinued (notably referenced as discontinued as of version 3.2.2.1), and customers are directed to migrate to enterprise licensing paths.
Storage is where Kubernetes stops being a scheduling system and becomes an operating platform. Stateless workloads are easy to move around. Stateful workloads force you to confront the hard problems that define day two operations, including volume lifecycle, performance under contention, node failures, upgrades, snapshots, backups, and restores. This is exactly the terrain where Portworx built its reputation, and it is also why the shape of its entry tier matters so much. Engineers do not learn Kubernetes storage by reading a feature matrix. They learn it by running real stateful apps, breaking nodes, testing backups, and validating recovery paths.
Portworx Essentials historically functioned as an on-ramp into that learning cycle, and Portworx’s own terms describe it as being provided free of charge up to usage limits. But the documentation now makes clear that this on-ramp is being closed. In the Portworx CSI documentation, a migration guide states that Portworx Essentials is discontinued as of version 3.2.2.1 and that clusters using PX-Essentials with a FlashArray or FlashBlade license cannot be upgraded to newer versions. Users are directed to either migrate to PX-CSI or migrate to Portworx Enterprise.
The Portworx Enterprise documentation is even more explicit about what happens next. It notes that with the discontinuation of Portworx Essentials, customers using the PX-Essentials license SKU will experience functionality restrictions when upgrading, and it spells out the impact once the Essentials license expires. Users will no longer be able to create new volumes, take snapshots, or perform new backups. The guidance is straightforward: to prevent service disruptions, users must transition from PX-Essentials to Portworx Enterprise.
That detail is not incidental. In Kubernetes, the ability to create volumes, take snapshots, and test backups is not an “advanced enterprise feature.” It is the core of how practitioners validate whether a storage platform belongs in production. Those are the exact tasks engineers perform in home labs and development clusters when they are building confidence. When the community tier is discontinued and the remaining path includes an expiring license that can remove fundamental capabilities, the experience stops feeling like a learning platform and starts feeling like a trial with a timer attached.
Portworx’s migration flow reinforces that enterprise-first posture. The documentation states that migrating from Portworx Essentials to Portworx Enterprise starts a 30-day trial license, and after that period a Portworx Enterprise license must be purchased to continue using enterprise features. It also warns that you cannot roll back from Portworx Enterprise to PX-CSI, and that migrating from Essentials to PX-CSI requires contacting support. This may be perfectly logical from a revenue and lifecycle perspective, but it raises the barrier to entry for the exact audience that typically becomes a product’s long-term advocate.
In the Kubernetes adoption flywheel, storage is not a category where teams casually switch later. Once you build around a storage platform, it becomes entangled with operational processes and recovery assumptions. That is why early hands-on confidence matters. When the easiest path to learn a storage platform is removed or time-bounded, engineers will learn something else that they can run indefinitely, experiment with freely, and trust without worrying that the first serious lab exercise will end in a licensing cliff.
That might be a clean revenue decision, but it also removes one of the easiest ways for engineers to learn the platform hands-on before they have budget authority.
Even Kubernetes’ own ecosystem shows the sustainability stress
This trend is not limited to commercial vendors tightening licenses or gating features behind subscription tiers. Some of the clearest warning signs are coming from Kubernetes-adjacent projects that were never designed to be “enterprise products” in the first place. As Kubernetes has become a foundational layer for modern infrastructure, expectations around security posture, release cadence, and operational reliability have risen sharply. The burden of meeting those expectations does not automatically scale with popularity, especially when maintainership remains concentrated in a small number of volunteers and part-time contributors.
Ingress NGINX is the most visible example because of how widely it is deployed and because it sits directly on the edge of the cluster as an internet-facing component. The Kubernetes project announced that Ingress NGINX is in best-effort maintenance today, and that in March 2026 maintenance will halt, and the project will be retired. After that point, there will be no further releases, no bug fixes, and no updates for future security vulnerabilities, even though existing deployments will continue to function. The announcement is direct about why this is happening: the project struggled for years with insufficient maintainership, often relying on one or two people doing development in their spare time, and accumulated technical debt where past flexibility became present-day security risk. The project also noted that attempts to transition to a replacement effort did not attract enough maintainers to become sustainable.
The same pressure shows up even in the “invisible” plumbing that keeps Kubernetes working at global scale. The Kubernetes project put a redirect in place from k8s.gcr.io to registry.k8s.io because the cost of serving image pull traffic at the old endpoint was not sustainable and risked exhausting project funds. The project also stated that k8s.gcr.io would be frozen after April 3, 2023, with no new images, releases, patches, or security updates, even though it would remain available temporarily to support migration. When the community must redesign its own global distribution path to stay financially sustainable, it is a reminder that “free” infrastructure still has very real operating costs.
CNCF has started to speak to this more openly as Kubernetes becomes the common infrastructure layer for AI and modern workloads. In its discussion of the latest Annual Cloud Native Survey, CNCF points to sustainability as an emerging challenge, warning that many systems operate on a “dangerously fragile premise” and that continued innovation depends on organizations contributing, supporting maintainers, and actively sustaining the ecosystem.
All of this reinforces the same macro trend. As Kubernetes adoption accelerates, especially under the pressure of AI and edge workloads, the ecosystem’s sustainability problem becomes impossible to ignore. If even Kubernetes-native projects can be forced into retirement due to maintainer scarcity and security burden, then tightening access and removing learning on-ramps in the commercial layer around Kubernetes is not just a pricing decision. It is a decision that compounds the fragility of the entire stack.
Why enterprise-first is a trap even when it feels rational

It is easy to understand why vendors are making these moves. Support is expensive, and the moment a project becomes part of the “default stack,” the support burden stops being optional. Security expectations are also higher than they have ever been, especially for components that sit on the edge of the cluster, store data, or influence traffic flow. At the same time, hyperscalers have proven they can package, host, and monetize open projects at global scale while contributing little back to the original maintainers. Add to that what enterprises actually demand once a tool becomes business critical, including SLAs, audit trails, certifications, and predictable lifecycle guarantees, and it is not hard to see why leadership teams feel pressure to tighten control and drive revenue through more enforceable licensing and tiering. Many of these shifts are understandable. They may even be necessary for some companies to survive.
But there is a trap hidden inside the logic, and it is one that infrastructure vendors have fallen into repeatedly. You cannot monetize what you do not have mindshare for. Revenue is downstream from adoption, and adoption is downstream from familiarity. If you remove the easiest path for engineers to learn, experiment, and build confidence, you are not just protecting margin. You are shrinking your future pipeline of champions.
Tech Stacks Tip Callout:
The First Hour Decides the Next Five Years
The most important UX moment in infrastructure isn't day 90, it's the first hour.
This is where the definition of a “community edition” matters. If what used to be a real on-ramp becomes something that is locked behind a portal, restricted from modification, limited to single-node only, missing the features that define real-world usage, or frozen in maintenance mode, then it stops being a community edition in the way practitioners mean it. It becomes a demo. It becomes a trial. It becomes a controlled marketing channel. Those things can still drive revenue in the short term, but they do not create the kind of deep, hands-on familiarity that makes engineers advocate for a tool when they are designing platforms under pressure.
The consequence is simple. The engineers who would have become your champions go elsewhere. They choose the alternative they can install on a weekend, run in a lab, and push into real scenarios without negotiating permissions first. And in 2026, elsewhere is not an empty space. It is a huge and growing universe of open projects, foundation-governed forks, and cloud-native alternatives that are actively competing for mindshare. The minute you close the on-ramp, you are not only raising the barrier to entry. You are creating an opening for the next default choice to take your place.
VMware’s playbook: free ESXi + certs + homelabs = a generation of evangelists
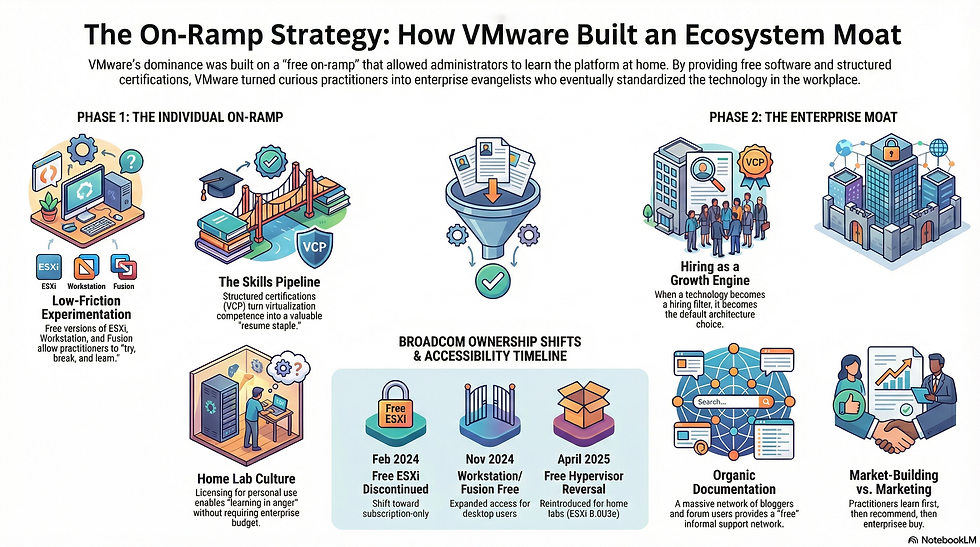
If you want a real-world example of why the free on-ramp matters, look at VMware’s rise. VMware did not become the default virtualization platform in so many enterprises simply because the technology was strong. It became the default because an enormous number of administrators learned it hands-on, often at home, and then carried that practical experience into the workplace. That kind of adoption does not start with procurement. It starts with curiosity, repetition, and the ability to build confidence without asking for budget.
For years, the free edition of ESXi, also known as the free vSphere Hypervisor, was one of the most effective “try it, break it, learn it” engines in enterprise infrastructure. It gave people a path to run a real bare-metal hypervisor, build small clusters, practice upgrades, and experiment with core operational workflows. Importantly, it did not just create hobbyists. It created future production operators. It can be easy to take for granted that free ESXi was often used for testing and tinkering, and that those experiences frequently led to production deployments or helped build the skills of IT professionals who later became champions of the VMware stack.
VMware also paired that on-ramp with a deliberate skills pipeline. Certifications and structured learning paths gave practitioners a clear way to level up, prove competence, and build careers around the platform. That matters more than people admit. When a technology becomes a resume staple, it becomes a hiring filter. When it becomes a hiring filter, it becomes a default architecture choice. VMware’s certification programs and the culture around them helped turn virtualization into a craft people could practice and advance in, not just a product they installed.
The story gets even more instructive when you look at what happened after Broadcom took control of VMware’s portfolio. In February 2024, Broadcom discontinued the free version of ESXi and marked it as end of general availability, tying the decision to the broader shift away from perpetual licensing and toward subscription. That move was widely interpreted as closing the door on the exact audience that had historically helped VMware maintain mindshare among practitioners.
Then, in April 2025, VMware reversed course and resumed offering a free hypervisor again, a change first spotted in the ESXi 8.0 Update 3e release notes. The reporting around this reintroduction made the subtext explicit. Free editions are a way to create test and training environments, and they are a way to build a talent pool. Broadcom later published a knowledge base article that provides clearer detail, stating that a free hypervisor version of ESXi 8.0U3e is available for standalone deployments, particularly for home labs and development or testing environments. The same article lists the limitations that separate it from enterprise editions, including no vCenter management and no vMotion, DRS, or HA, along with API limitations and no official support.
In parallel, VMware has continued to reinforce the learning pipeline through licensing programs tied to skills. The VMware Cloud Foundation blog promoted free, personal-use vSphere Standard licensing for certified professionals and described the virtual lab as essential for hands-on learning. The VMware {code} blog also published a practical guide that lays out home lab licensing options tied to passing VCP exams and, for larger personal-use bundles, maintaining VMUG Advantage membership. The guide is explicit that these are personal-use licenses intended for learning and experimentation, not work environments. VMUG’s own FAQ document similarly describes how the home lab licensing pathway changed in late 2024, with access to full-stack personal-use licensing tied to certification status and VMUG Advantage membership.
Even on the desktop side, VMware made its Workstation and Fusion products free for all users beginning November 11, 2024, which further lowered the barrier to experimentation and lab building.
The exact licensing details have shifted over time, and they may continue to shift. The lesson is still the same. VMware understood that training plus home labs create an ecosystem moat. They built a system where people could learn the platform without friction, prove competence through certifications, and then bring that competence into enterprise environments where standardization decisions are made under pressure.
They cultivated a following of practitioners who became:
· the informal support network that reduces friction for new adopters
· the how-to blog writers and lab builders who create the real documentation
· the forum answerers who turn incidents into shared knowledge
· the hiring managers who screened for VMware skills because they trusted what they signaled
· the architects who standardized VMware at work because they had already used it in anger
That is not marketing. It is market-building. It is what happens when a company treats accessibility and skills development as part of the product strategy, not an afterthought. And for VMware, it worked because it aligned with how infrastructure actually spreads. Practitioners learn first, then they recommend, then enterprises buy.
The opening this creates: community-forward projects can capture the next wave
When incumbents tighten the on-ramp, the market does not stop learning. It reroutes learning. The same engineers who used to build confidence by spinning up a community edition in a home lab will still build confidence, but they will do it with whatever is easiest to run, easiest to understand, and safest to standardize on later. In other words, when a widely used project moves from community-first to enterprise-first, it does not just create frustration. It creates opportunity for the next default.
You can already see how this plays out in real time. In infrastructure as code, OpenTofu exists specifically to preserve Terraform-style workflows under neutral, community-driven governance after HashiCorp’s licensing changes, and it is explicitly positioned as a community-led successor that prioritizes stability and backwards compatibility. In caching and data structures, Valkey was formed as a BSD-licensed continuation in direct response to Redis licensing changes, keeping an open path alive for teams that want Redis compatibility without legal uncertainty. And on the traffic management front, the Kubernetes community has been increasingly clear that Gateway API is the successor to the Ingress API, which creates a natural consolidation point as the ecosystem shifts away from legacy ingress patterns and toward more expressive, role-oriented routing models.
This is where projects like the ones you called out can step up, not just as alternatives, but as the next wave of defaults. The playbook is straightforward. Stay community-forward, keep the on-ramp open, make it easy to get hands-on, and offer a clear path to enterprise adoption without turning the learning tier into a dead end.
Calico: an open-source foundation with a clear enterprise path
Calico is a strong example of how to balance openness with commercialization without breaking the adoption flywheel. Project Calico is explicitly positioned as free and open source with an active community, and it is maintained by Tigera. That means a new engineer can install it, learn Kubernetes networking and policy in a lab, and build real confidence without needing approval or budget. The enterprise path still exists for organizations that want additional capabilities, support, and governance, but the foundation remains accessible enough that Calico can continue to be a skill people develop early in their Kubernetes journey.
In the context of the current market shift, that matters. Networking and security are not bolt-on concerns in Kubernetes. They shape cluster design, platform standards, and day-two operations. A project that stays open at the learning layer while offering enterprise value on top is positioned to absorb mindshare as other vendors restrict access to experimentation.
Isovalent and Cilium: CNCF graduation plus eBPF momentum
Cilium is another clear beneficiary of this moment. Its CNCF graduation signals maturity and staying power, and that is not a small thing for platform teams that need confidence in operational stability. Cilium also sits at the intersection of networking, security, and observability, which aligns directly with where Kubernetes stacks are going. As clusters grow more complex and workloads expand into AI, edge, and multi-cluster architectures, teams want tools that reduce fragmentation across these layers.
Cilium is not just a project with strong technology. It is a project with ecosystem gravity. It offers a credible open-source base that engineers can learn in home labs, plus a commercial ecosystem that can support enterprises that need more than community support. That combination is exactly what becomes attractive when competing tools start closing off the learning path.
Garage: S3-compatible object storage built for self-hosting
On the object storage side, Garage is precisely the kind of project that can grow quickly when a market leader tightens control. Garage positions itself as an open-source distributed object storage service built to suit existing infrastructure and implements the Amazon S3 API, which makes it immediately useful and immediately testable. The barrier to entry is low, the self-hosting story is explicit, and that makes it a natural fit for home labs, small clusters, and edge deployments where teams want S3 semantics without a cloud dependency.
This is the most important attribute in the current environment. Engineers need a place to learn and validate patterns for artifacts, backups, datasets, and ML pipelines. When the easiest path becomes gated, they gravitate toward projects like Garage that let them build confidence without constraints.
SeaweedFS: Apache-licensed, pragmatic storage with S3 support
SeaweedFS is another practical candidate for this wave. It is an Apache-licensed open-source project and explicitly calls out an Amazon S3 compatible API, which is a big deal because S3 compatibility is the common language of modern storage workflows. SeaweedFS also tends to resonate with engineers who value pragmatic deployment and understandability, because it presents itself as a system you can run and reason about, not just a service you consume.
In a world where community tiers are disappearing, Apache licensing and S3 compatibility create a very clean learning story. Engineers can practice object storage patterns in a lab with familiar tooling and carry those patterns forward without worrying that the learning version is fundamentally different from the production version.
More projects that fit the pattern
The opening is broader than any single category, and a few other projects deserve to be on the short list because they reinforce the same theme.
OpenBao exists as a community-driven fork of HashiCorp Vault managed by the Linux Foundation, which gives teams a path to learn and standardize secrets management without betting on a licensing or governance shift.
Longhorn positions itself as 100% open-source cloud-native persistent block storage for Kubernetes, which directly competes with enterprise-first storage offerings by making hands-on learning straightforward.
OpenEBS is now a CNCF project at the Sandbox maturity level, offering another open path for Kubernetes-native storage patterns as teams evaluate alternatives in the stateful layer.
None of these projects win automatically just because they are open. They win if they execute on the adoption flywheel.
What “stepping up” looks like in 2026
For community-forward projects, this market inflection point is a once-in-a-cycle chance to capture mindshare. The winning moves are not complicated:
· Make the first hour frictionless with real Kubernetes installs, not demos
· Publish migration guides from incumbent products and common patterns
· Keep licensing stable and contribution paths open
· Invest in documentation, quickstarts, and repeatable lab workflows
· Offer paid support and enterprise features without making the learning tier a dead end
These projects have an opportunity right now that only shows up when incumbents close doors.
Be the tool people can learn for free, and they will bring you into production later.
What vendors should do if they want to win the Kubernetes era
If you are a vendor sitting on a popular infrastructure component, I do not think the answer is to give everything away forever. Sustainability matters, and it is reasonable to expect that enterprises will pay for support, compliance, scale, and guarantees. But there are clear patterns that preserve sustainability without killing the on-ramp, and the vendors who internalize them will be the ones that keep mindshare as Kubernetes adoption continues to accelerate.
1. Keep a true personal-use or homelab tier
Make it a real learning tier, not a marketing demo. If clustering and high availability are fundamental to your product, do not make the free path single-node only. Engineers need to practice the real workflows, not a watered-down version that teaches them the wrong lessons.
2. Make the first hour frictionless
No sales calls. No procurement steps. No “contact us to get started.” The first hour is where engineers decide whether a tool feels intuitive, operable, and worth investing time in. If you add friction before they reach value, most will not try again.
3. Offer certifications and hands-on learning paths
Certifications are not vanity credentials when they are paired with real labs and practical outcomes. VMware proved that a strong certification ecosystem creates durable market gravity by turning a tool into a skill and a skill into a hiring signal.
4. Be transparent about what is open, what is gated, and why
Engineers do not mind paying for value. They mind surprises. If features are gated, say so clearly. If the license has restrictions, explain them plainly. If the open project is limited or shifting, communicate it early and directly so teams can plan.
5. If you must tighten licensing, do not be shocked when forks win mindshare
OpenTofu and Valkey are not anomalies. They are the predictable response to uncertainty and broken trust. When the on-ramp closes, the ecosystem does what it always does. It creates another way in.
What practitioners should do right now
If you are building or standardizing platforms on Kubernetes, treat licensing and community access as architecture decisions, not procurement details. In a Kubernetes-first world, the “default stack” is assembled from primitives that become deeply embedded in delivery pipelines, security controls, and operational playbooks. When one of those primitives changes licensing, governance, or community posture, it can force migrations, retooling, and unplanned risk. Those are architectural consequences, even if they show up first as a contract change.
A practical checklist:
1. Inventory which dependencies have community tier risk
Do not limit this to your biggest line items. Look at the entire chain, including storage, ingress, registries, CI/CD integrations, observability agents, backup tools, and any operator-managed components. If the learning tier disappears or the license changes, can you still onboard new engineers and reproduce environments reliably?
2. Prefer projects with neutral governance for critical primitives
Foundation-backed projects and open roadmaps are not a guarantee of perfection, but they reduce the risk of sudden policy shifts that break the community contract. For core layers like IaC, networking, secrets, ingress, and storage, neutrality and predictability matter as much as features.
3. Build escape hatches before you need them
“We can migrate later” is not a plan unless you have tested it. Define compatibility layers, keep your configurations portable, and validate alternatives in a sandbox environment. Know what it would take to swap an ingress controller, replace a storage backend, or move off a proprietary operator without rewriting everything under time pressure.
4. Reward healthy ecosystems
If a project is essential to your platform, treat its health as part of your risk management. Contribute code, improve docs, sponsor maintainers, participate in the community, or at minimum choose vendors that keep the learning path open and invest in long-term sustainability. The tools you support today shape what will still exist tomorrow.
Because in a Kubernetes world, you are not just choosing software. You are choosing which ecosystems get stronger, which projects your teams will learn first, and ultimately who gets to shape your engineers’ skills over the next decade.
Tech Stacks Tip Callout:
Watch the On-Ramp, Not the Price Sheet
The most reliable signal of long-term platform success isn't pricing, it's who's allowed to learn it freely.
Closing thought: the next VMware is being created right now
Kubernetes is pulling more workloads into a single operational gravity well. AI inference is becoming a first-class production workload. Data pipelines are increasingly Kubernetes-native. Edge deployments are standardizing on the same primitives used in the cloud. The CNCF numbers reinforce what most platform teams already feel day to day: Kubernetes is no longer a special project. It is the operating layer for modern infrastructure, and its footprint is still expanding.
When the stack consolidates like this, the competitive battleground shifts. The winners are not determined solely by feature checklists or procurement leverage. They are determined by ecosystem gravity. The tools that become defaults are the tools that engineers trust, and engineers trust what they have used, broken, repaired, and learned deeply. That trust is not created in a conference keynote. It is created in a home lab, a dev cluster, and a weekend spent chasing down why something failed under load.
Ecosystem gravity starts with the on-ramp. If the old guard walls off the first mile behind licensing gates, friction-heavy portals, and restricted “free” tiers that cannot be meaningfully explored, they will slow their own future adoption. The market will not wait. It will route around them. It will choose projects that are accessible, legible, and safe to bet on. It will create forks. It will elevate alternatives. And the engineers who drive platform decisions will build their confidence somewhere else.
That is the call to action, and it applies to both sides of the equation.
If you are a vendor, decide what kind of ecosystem you want to build. A gated funnel might maximize short-term conversion, but an open learning path maximizes long-term dominance. Keep the first mile open. Invest in documentation, labs, and certification-grade learning experiences. Build a real personal-use tier that reflects how your product is actually used. Give practitioners a reason to choose your tool before they have budget authority, and they will carry it into the enterprise when they do.
If you are a practitioner or a platform leader, stop treating licensing as a footnote. Make it part of your architecture review. Standardize on primitives you can teach, reproduce, and sustain. Support the ecosystems that keep learning accessible, because the tools your engineers can practice on today become the tools your organization can confidently deploy tomorrow.
The next VMware is being created right now. Not because one company will replicate virtualization’s history exactly, but because the same dynamic is happening again at a larger scale. Whoever earns the loyalty of hands-on builders will earn the enterprise later. The future is not just Kubernetes. It is Kubernetes plus the tools engineers are allowed to learn freely, master early, and recommend with confidence when it matters.


Comments